
The Scholars’ Lab is pleased to announce the first release of the SolrSearch Omeka plugin.
SolrSearch allows you to replace Omeka’s default search with Solr. Solr is a standard, popular, open source, fast text search engine server. It handles hit highlighting, date math, numeric aggregation functions (mean, max, etc.), indexing for 33 languages, replication, and many, many more things. It’s used by whitehouse.gov, Instagram, AT&T;’s yp.com, Ticketmaster, and Netflix, to name a few (see the list of Public websites using Solr).
It does require running Solr as a separate server process (although possibly on the same machine), so it does require more resources–both personnel and technical–but it’s often worth the investment.
Search Pages and Exhibits SolrSearch now indexes Simple Pages and Exhibits.
Performance Did I mention that Solr is fast? It’s been optimized for high-traffic sites, and it can easily handle much more data than MySQL full text search can.
Scalability And because it’s been engineered for large, high-traffic sites, Solr can handle more data, faster than MySQL. This especially becomes an issue when you have collections with a large number of items or items with a lot of data attached to each.
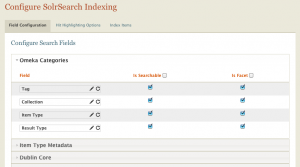
Configuration The SolrSearch plugin in highly configurable. You can decide which fields to search, which can be used for facets, and how to label them.
Facets Facets slice up your items and allow users to navigate through those slices. For example, The Falmouth Project used an early version of the SolrSearch plugin to give users not only free-text search, but also to allow users to browse the buildings it records by neighborhood, date, and use.
You can find the download on the SolrSearch plugin page. The code is hosted on the SolrSearch github page. If you have any feedback about the plugin, find any bugs, or want to suggest features, head over to the issues page. And if you have questions, feel free to post in the Omeka forums.
As always, we look forward to seeing how you’ll use this.