
At MLA 2021, I was part of a panel on “Perspectives on Digital Humanities Publishing” along with Jojo Karlin and Matthew K. Gold; Radhika Gajjala; and Gabriela Baeza Ventura and Carolina Villarroel. The lightly edited text of my talk follows along with my slides. As always, I tend to use the text as an outline and then expand or contract sections in the moment. More information on that strategy for public speaking can be found here.

Hello! I’m Brandon Walsh, Head of Student Programs in The Scholars’ Lab, a center for digital research in the University of Virginia Library. I’m also on the editorial board for The Programming Historian, and I’ll be talking today about the editorial processes we use to guide new lessons from submission to publication. In particular, I’ll be focusing on the technical platform we use for these workflows and how those technologies intersect with and inform the process itself.

I wanted to express gratitude up front to my co-presenters and to those whose work feeds into this talk. I, of course, need to thank the entire Programming Historian team, but it feels especially important to thank and acknowledge the non-English language teams working on the project–the Spanish, French, and (very soon!) Portuguese versions of the journal–since much of what I am discussing today focuses on their work. I should also acknowledge Matthew Lincoln, formerly the technical lead for the project, for the enormous labor he put into the technical infrastructure and workflows I’ll be discussing. And I also wanted to thank Jennifer Isasi, because the analytics I will mention came directly from her year-in-review blog post for the project.

By way of a roadmap – here’s what I’ll be discussing. After some brief background on the Programming Historian, I’ll discuss our editorial process and the technical platform, GitHub, we use to carry out those discussions and reviews. In particular, I’m going to highlight the costs and affordances of two aspects of it:
- the slow, deliberate nature of working with the platform that enables translation and
- the ways in which the platform force us to be extremely open and transparent.
And also, in case it’s useful for your ability to follow along with the talk, there is a link here to the rough text and slides of what I’ll be sharing.

Founded in 2008, The Programming Historian is a set of federated, open-access, and openly peer-reviewed journals that publishes novice-friendly articles on a range of different digital tools and workflows. The articles sit at the intersections of pedagogy and research. The idea is that someone who has, say, done work on network analysis with a particular corpus might then take that project and use it as a case study for a lesson with us that describes how others might perform network analysis themselves.
The project began by publishing in English and now includes 83 lessons in that language, but significant effort in recent years has been directed towards growing the project into other languages and for other communities. At this time of writing, the project contains 47 lessons in Spanish, 14 lessons in French, and a Portuguese version is soon to launch. We had 1.5 million visitors last year, but only about one third of those came from North America or the United Kingdom (more detailed analytics here). We work hard to think about this international audience. While the majority of our pieces right now originate in English, The Programming Historian has begun to receive original material in Spanish. And our goal is to accept original work in our other represented languages as well. A significant amount of the labor of the people on these project teams is directed to building the audience for their particular journals. Translating 80 lessons into a language like French is an enormous undertaking, and, in doing so, the editorial teams working in French aim to cultivate and engage with digital humanists working in that language who can then return to contribute their own original work.
But that is all subject for another talk. I have been on the English and technical teams for several years now, so I’m primarily going to be describing how we set up and facilitate the editorial processes that these non-English teams work through as they facilitate their massive translation projects.

Programming Historian began as an English-language publication, but now it is a set of journals with interlocking pieces. What I mean by that is that we have a set of journals that all share core architecture – general editorial guidelines, submission guidelines, and processes are shared among the journals. The public-facing pages for these components are all translated and kept in synch with one another if they change. These language-specific publications all use the same technical platform for submitting and reviewing work. But the translation projects are in various stages of completion, and the non-English journals are beginning to accept original lessons in their own languages. So core shared elements, but each journal acts independently according to their own timelines for production.

The primary thing I want to focus on today is how editorial activities intersect with technical platforms and the implications those technical choices, in turn, have for the identity, vision, and actions of the journals themselves. Parts of our process are quite familiar to other kinds of academic publishing workflows: we receive submissions by email, give editorial feedback upon accepting something for review, conduct open peer review, integrate feedback, etc. A few notable elements might be that we have a fairly turnaround from pitch to publication (six months to a year), we ask for pitches upfront rather than full manuscripts, and once we accept something into the review pipeline, we try to work generously with authors to see a piece to publication as much as we can. These pieces, in particular, are key to the vision of the project as we try to shape it.
These activities take place almost exclusively (save a few introductory emails) on a platform called GitHub. GitHub collects a suite of tools associated most closely with software development together, and I’ll go through a few that we’ve adapted for our editorial process along with the implications for doing so.
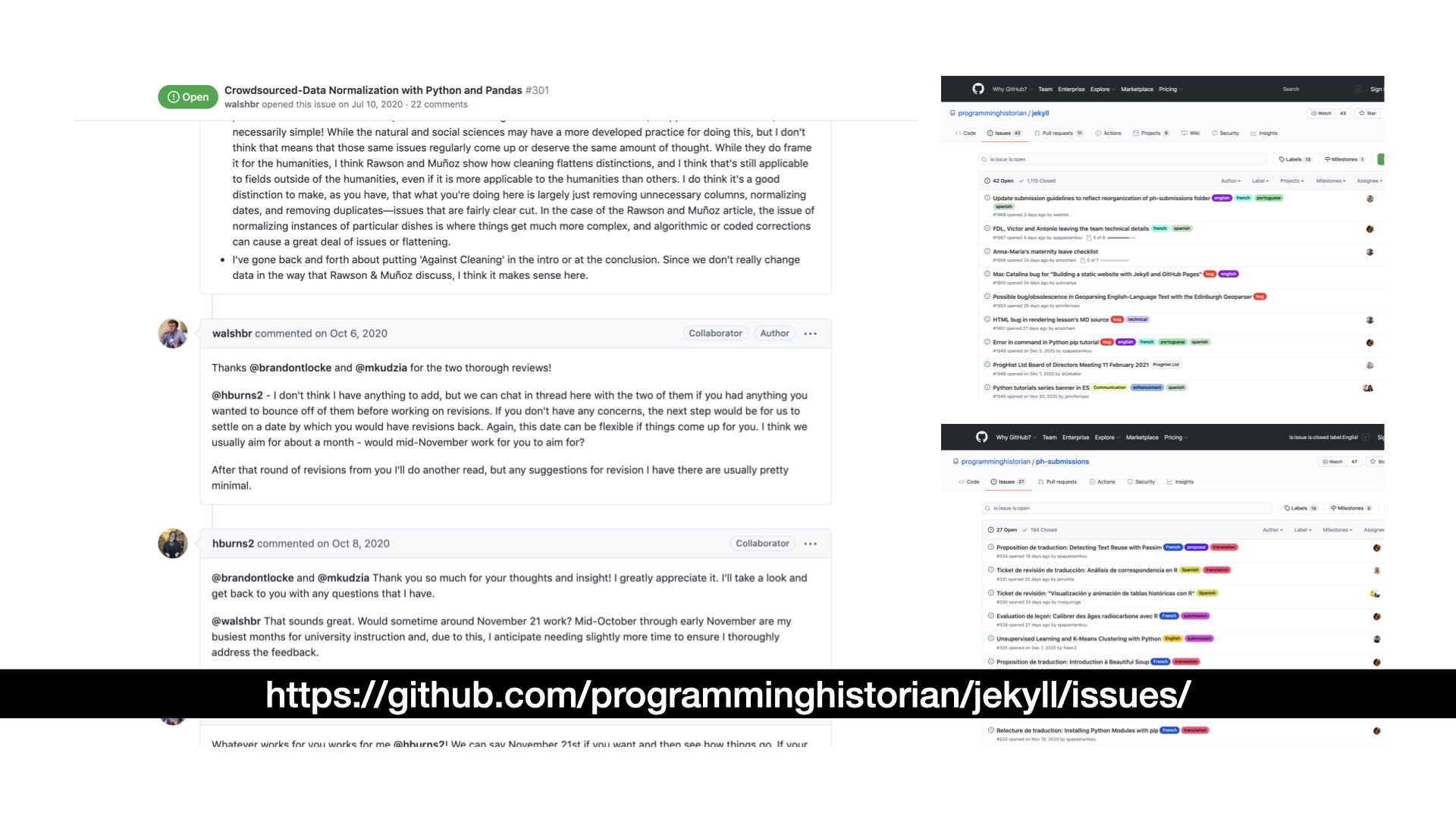
First, GitHub contains a suite of project management tools, and our peer review pipeline takes place in this system. In particular, we make heavy use of GitHub’s issue tracker for coordinating conversations about particular topics. Typical uses in the software management world for these tickets might be to collect information for acting on a bug report or gather conversation on a new feature. We lean on the conversational aspect of these tickets to manage our open peer review process. A new submission that has been accepted into the pipeline gets a new ticket that states where to find the lesson, shared expectations, and the editorial review of that piece takes place in public on this thread. Sometimes the public joins in unexpectedly, offering an unsolicited review or with words of encouragement about the new work. When we solicit reviews, they typically come in through this system. In addition to our review process, we handle 95% of internal conversations about the journal itself on this system which, again, periodically gets unexpected input from others outside the team. You can see here on the left an example review ticket on data normalization using pandas that I share with the author’s permission. On the right, you can see various editorial conversations about everything from bug reports to open debates about the identity of the project. They’re all happening in public.
A second aspect of the platform that we make substantial use of is GitHub’s file management system. GitHub makes use of Git, an extensive system for managing and resolving the changes made to files by groups of people. We actually use it for the work of managing the materials for our website itself. More on that in a second, but I first just wanted to give an example of what I mean by this sort of shared file management.
I imagine most people are probably more familiar with using Dropbox or Google Docs for collaborative authorship. Under those systems, the changes you make to documents are, usually, automatically synched. So, in this example, Fred or Lisa make changes to a shared Google Doc document that they can all see in real time. This is great in a lot of ways and has great implications for research and teaching, but it also has drawbacks. We’ve all been editing a Google Doc with a group of people when someone makes a huge change, shifting everything out of order. Not a big deal when you’re editing text, but when working with software you have to be more delicate about collaborating on your files. What distinguishes GitHub is that it is optimized for comparing changes on a line-by-line level. Rather than synching changes automatically, each part of the process – saving a change, sending it up to the cloud, retrieving someone else’s changes – requires its own command. So you can imagine how this process becomes much slower and more tied to each person’s identity. We can more easily pull apart the changes made by Lisa from those made by Dave. And when Dave inevitably messes up the project we could isolate his problematic changes and remove them. This core idea of shared editing in a slow, deliberate manner is something most of us regularly engage with. But because GitHub breaks out this editing process into so many steps (and adds an esoteric layer of vocabulary to each part of the process), the system is often very confusing for people.
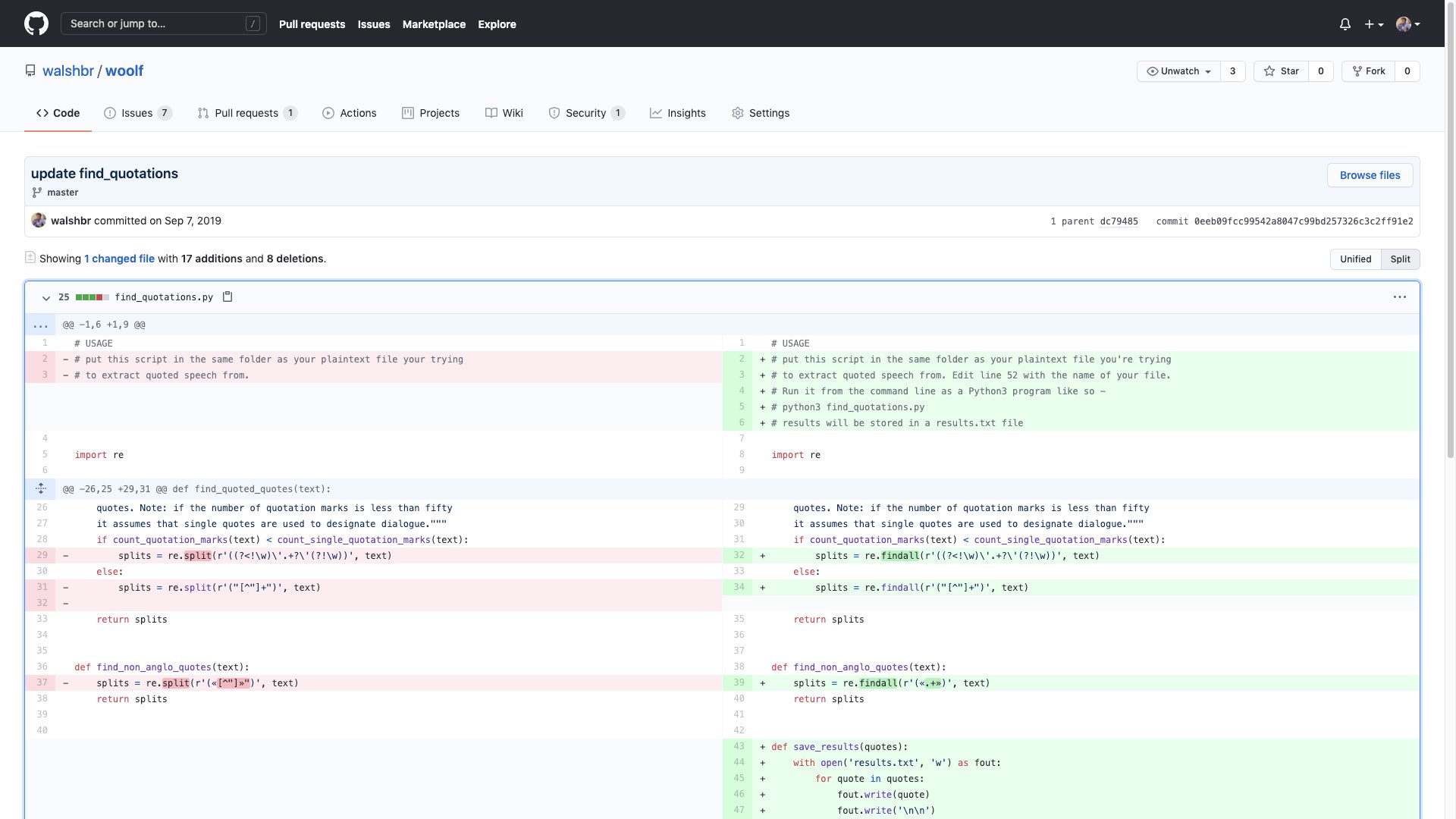
GitHub is typically used for software development, so I wanted to start with an example of using it for just that. Before you is a typical example of what a change to a file looks like in GitHub’s interface for viewing them. GitHub calls this change a “commit,” and you’re looking at a representation of that change’s differences (a “diff”). This is from an old project of mine doing text analysis on punctuation in Virginia Woolf. I had found that the particular way I was searching for quotation marks wasn’t quite right, so I updated it. Looking at this diff briefly, GitHub makes it clear what I changed. Changes in red mean a line was subtracted, green means a line was added. So, you can see at a glance what was changed without having to do much visual collation on your own and without needing to be familiar with the project.
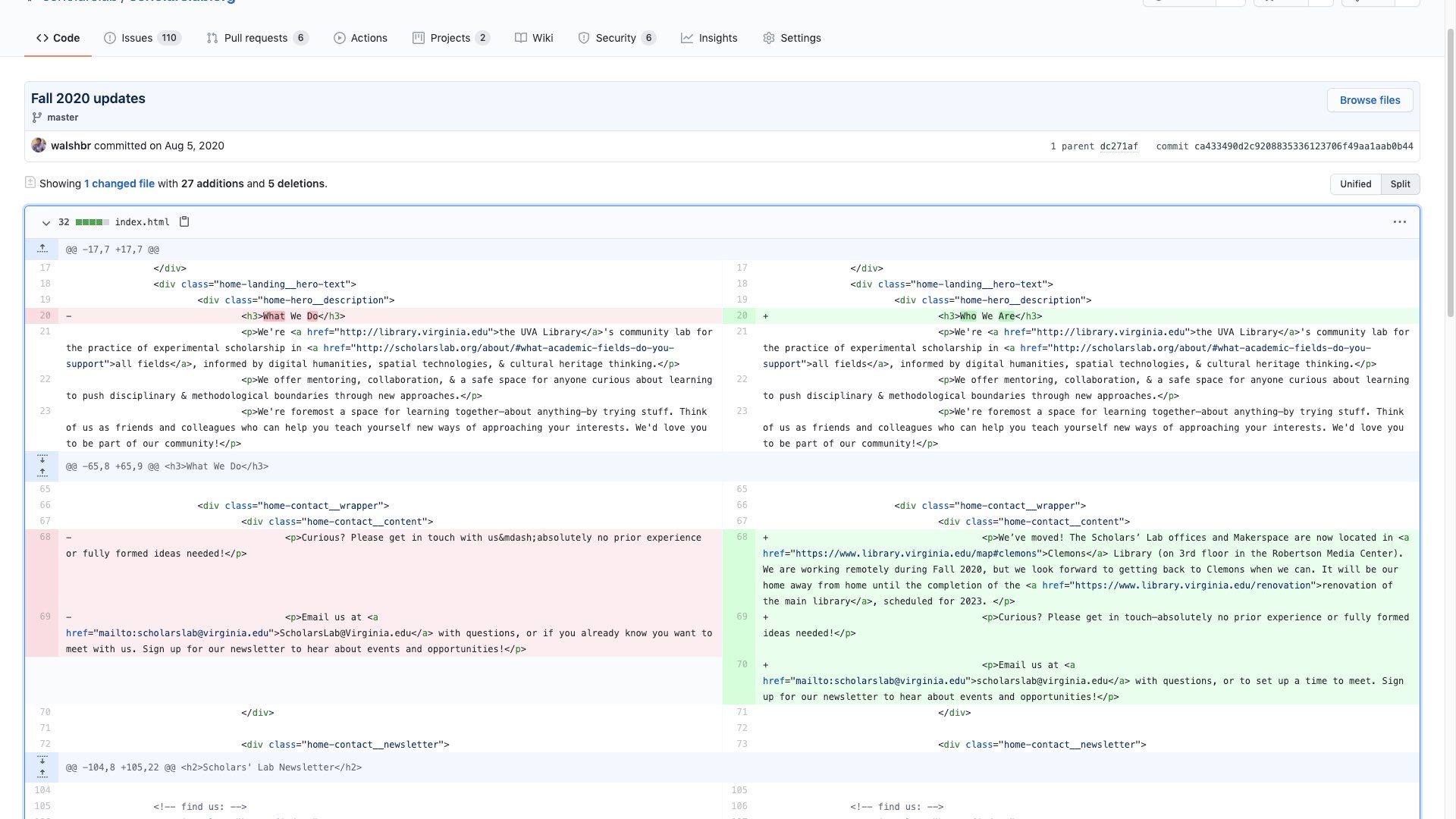
Here’s another example. On the Scholars’ Lab website we made a change to the markup for our blog, the information that tells your web browser how to display the site to visitors. Here we change, among other things, the phrase “who we are” to “what we do.” I bring up this example, in particular, because it moves in the direction of the kind of work we do as digital humanists. Digital projects represent a great deal of intellectual work, and that labor becomes bound up in the technical processes with which we carry them out. Here, the process by which we describe the lab for the web here is visible alongside the technical architecture for it. The self-formulation, the writing, is a part of GitHub. And it happens in public.
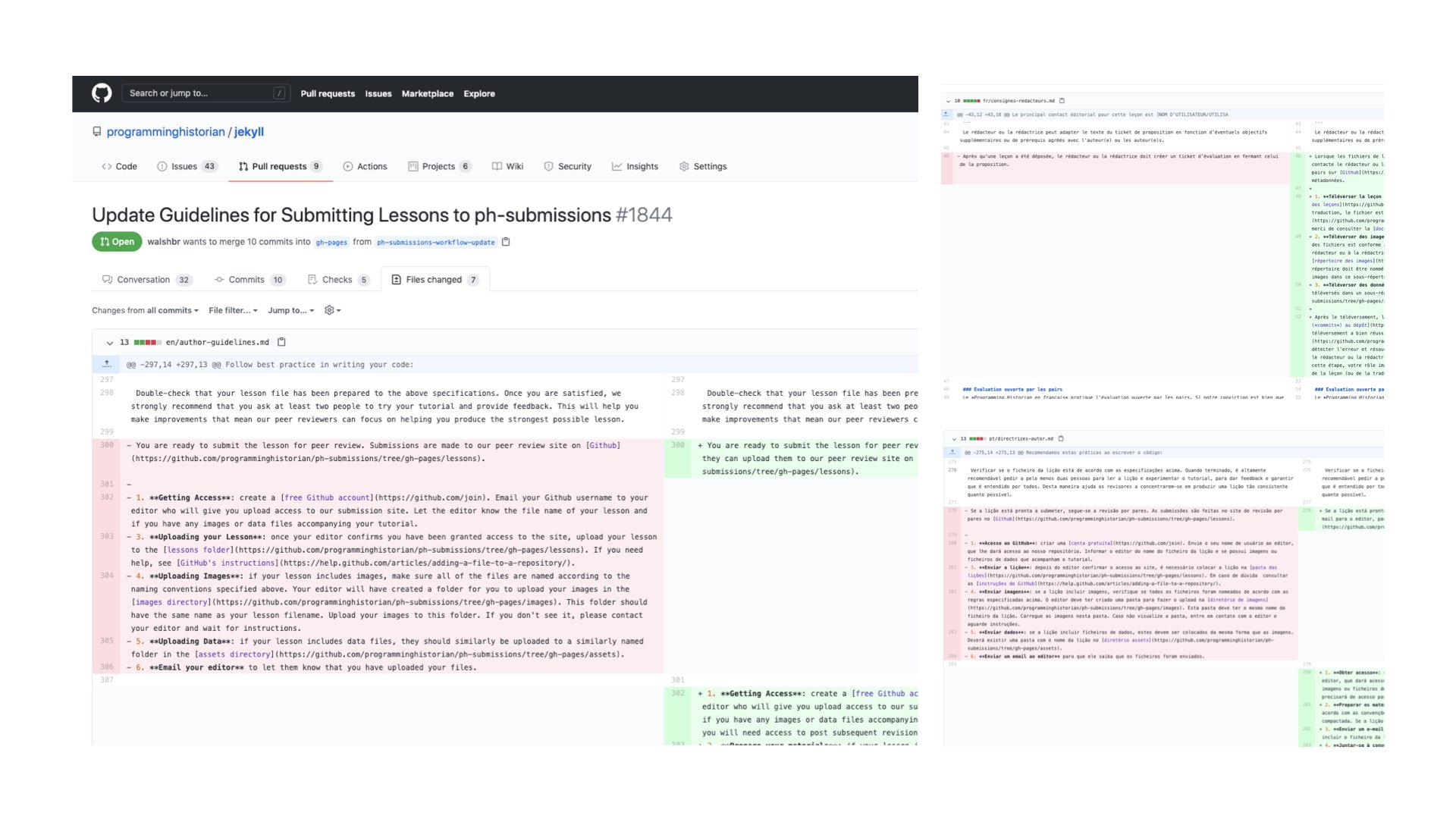
Here is one last series of diffs that I wanted to show from the Programming Historian’s presence on GitHub. We take advantage of this slow, belabored way of making changes as a means of facilitating translation work for the site. Lessons are translated in whole units. But I mentioned that we have core architecture for each journal that we want to stay relatively in synch. This is made complicated as the process by which we do things is constantly evolving. In the past few years, we have shared new guidelines for how to write sustainably, advice for how to write with an international audience in mind, and numerous changes to our submission process. Each of these changes has text that needs to be translated across the different language editions, and we want to make sure that things are current and not in various stages of completion. So, we use GitHub’s system to coordinate our efforts. What you see here is a change we are currently making to our editorial guidelines. I offer the new text for the change in English, flag the changes using GitHub’s system, and then the language teams use this interface to coordinate and manage the translation process. So here a few paragraphs get offered in English on the left, translated to French in the top-right diff, and translated to Portuguese in the bottom-right.

This process has several effects on our work. First, it means that any changes we make to our public-facing documents take a while to implement, because we make sure that all our public-facing changes almost always go into effect in all languages at once. Second and more importantly, this process has been especially useful for making the English team aware of the labor of translation. Any change we want to propose has ripple effects for the other teams downstream, so it helps to surface the human cost of tinkering with process. The English-language team is not the only one offering changes to the process that requires such work, but, perhaps because we have been working longest, I think we tend to be the most frequent culprits.
When it comes to our core site documents, we think of translation as a key part of our process that happens on an ongoing basis rather than something that happens after the fact. Besides the logistics of the process, this also raises the visibility and legibility of translation and internationalization as key parts of our process. The non-English language teams have done extraordinary work to ensure that we think of lessons that come into our pipeline as being bound for an international audience rather than solely as meant to live in a single language. Because of the advocacy and input of these teams, the project developed some guidelines for authors and editors on avoiding regionally specific language and ways to think about how to best structure a lesson for an international audience. And we’ve been discussing internally about whether some DH methods might be less translatable at their core and the implications this might have. All of this is to say that in terms of process and even down to technical architecture, we’ve been working hard in recent years to transition away from an English-first approach to editorial work and towards one that encourages many points of entry, with English just serving as one potential path in.
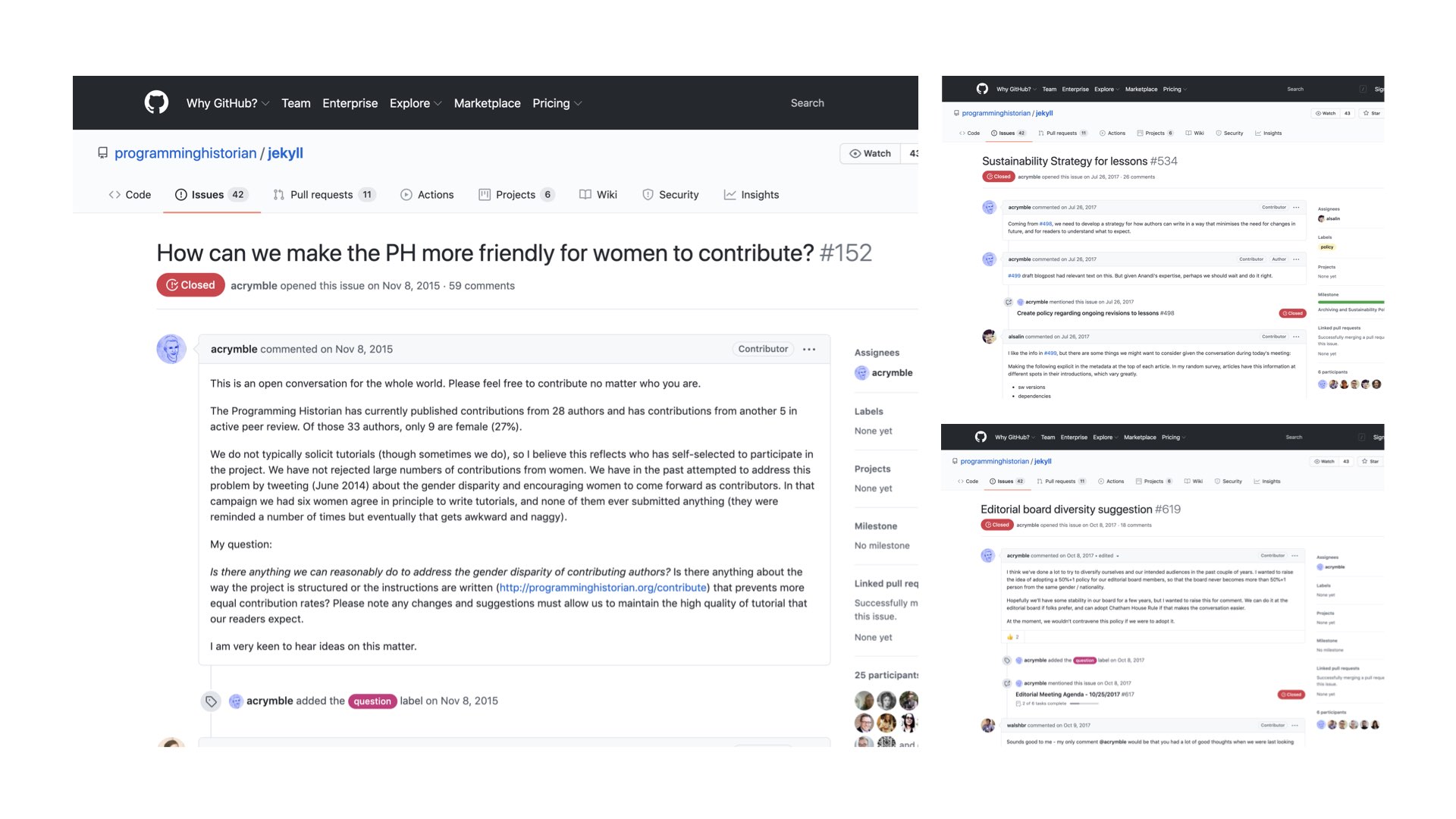
Another result of carrying out our work on GitHub is that the platform is heavily biased towards open. The project is as well. Our peer review and our technical architecture are public, but we’ve embraced this ethos to hold most of our editorial conversations in the open, meaning our churning is out there for anyone to see (or join in on!). Just as a few examples, on the top-right here is a screenshot of the conversation thread that lead to our sustainability guidelines. The other two conversations relate to ongoing efforts to make our editorial board, our authors, and our reviewers more diverse and friendlier to participants of a variety of genders. This work is far from finished. If you look at these threads and others, the project is frequently taken to task – internally and externally – for ways in which we can be better. In the same way that our lessons are openly peer reviewed, you might say that the journals themselves are constantly under open review. We’re in a perpetual state of revise and resubmit.

I also wanted to offer a few thoughts on the costs of this way of working. As I mentioned, we can move quickly in some ways but are quite slow in others. Our rolling deadline and quick publishing timeline make us quite quick by academic standards. But making changes to the underlying architecture and documentation of that editorial process, as evinced by the translation diffs I showed you, is an extremely slow and deliberative process. As I hope I have made clear, I actually think this is a very good thing, in that it helps us to think beyond a single language, makes more visible the labor that goes into translation, and increases collaboration across teams working in specific languages. But it should still be noted as an effect of the technical choices we have made.
Second, there are limits to how you can ethically carry out an open peer review process. No matter how much encouragement you give to people to be positive and generous in their readings, sometimes you get reviewers who are blunt or cruel. And no matter how much you work with an author, sometimes a work is not quite to a stage where it can be published. In situations like these, authors need the ability to opt their work and its review history out of the open – the stakes of such things for early-career scholars are just too high. Because we’re so tightly integrated with GitHub, which prioritizes openness and exhaustive record-keeping, it can be difficult to truly wipe something from the project history. It can be done, but doing so is a tad difficult because it works a bit at cross purposes to being on GitHub in the first place. So this bias towards an open archive is one caution I would offer to those considering carrying out editorial work in an environment like this.
One last thing I would note is that carrying out editorial process through GitHub is difficult and complicated. It requires a fair degree of technical fluency that most editors (and some authors) do not have when they come to work with us for the first time. Matthew Lincoln, who I mentioned early on, did an extraordinary job documenting in exhaustive detail how to work in this system, and we still regularly have issues. This is a common issue with “minimal computing” approaches to doing digital work, of which our project is an example. Our site uses a classic minimal computing stack – a Jekyll project coordinated and deployed through GitHub. This means that, from a technical standpoint, our work is more sustainable and requests less computing power for visitors. It also means that we’re pretty tightly in control of much of our publishing process and can change the look and feel of the project ourselves. But the cost is that we ask quite a lot of our editors to engage with the system, and it takes a lot of careful collaboration, assistance, and pair programming to make sure people are able to contribute.
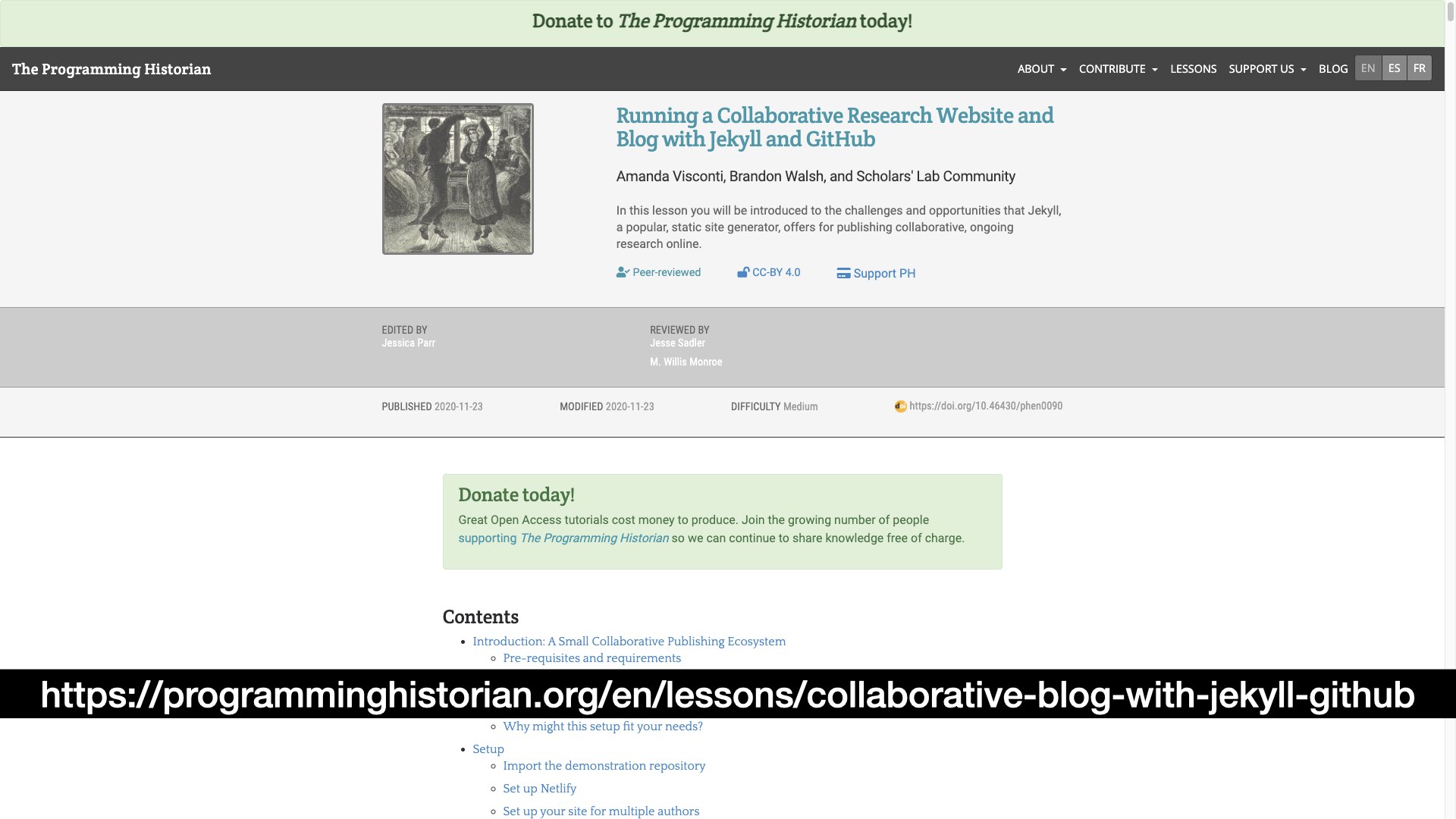
If I haven’t scared you off with my last slide, I wanted to close with a resource in case you’re interested in learning more about how to implement this kind of pipeline on your own. The process for collaborative authorship I described here need not only apply to peer review journals. I mentioned that we applied a version of this system to the Scholars’ Lab blog, and I published a piece in the Programming Historian with Amanda Visconti and the Scholars’ Lab community that documents this process. We don’t cover how to internationalize your work and facilitate its translation. Lincoln has published a great blog post on how the Programming Historian does this piece in particular. But we do cover how to take a site meant for one person and turn it into a multi-author site with a pipeline for collaborative peer review. So, if you’re interested in setting up your own collaborative publishing space for a team you’re involved with you might check out that link.
That’s it for me – thank you very much!
Addendum: I got one question during the Q&A about how to convince other people to adopt this sort of stack for their own work. My response was to lean on the “costs” slide that I offered towards the end of the talk. Rather than assuming everyone needs to develop a pipeline like this in GitHub, I think any project team needs to look at their needs and the abilities of their group before committing to a system like this. To a large degree, this decision becomes a question of where your team wants to invest their energy. For some, that might very well be the kind of minimal computing setup we have here. For others, WordPress might make more sense. Our Programming Historian article has a short section on how to diagnose these needs and think about the costs and benefits of each.
Jojo put together an incredible sketch of the panel participants as we spoke. Sharing with her permission!
