FedoraConnector 2.0

Hot on the heels of yesterday’s update to the SolrSearch plugin, today we’re happy to announce version 2.0 of the FedoraConnector plugin, which makes it possible to link items in Omeka with objects in Fedora Commons repositories! The workflow is simple - just register the location of one or more installations of Fedora, and then individual items in the Omeka collection can be associated with a Fedora PID. Once the link is established, any combination of the datastreams associated with the PID can be selected for import. For each of the datastreams, FedoraConnector proceeds in one of two ways:
-
If the datastream contains metadata (e.g., a Dublin Core record), the plugin will check to see if it can find an “importer” that knows how to read the metadata format. Out of the box, the plugin can import Dublin Core and MODS, but also includes a really simple API that makes it easy to add in new importers for other metadata standards. If an importer is found for the datastream, FedoraConnector just copies all of the metadata into the item, mapping the content into the Dublin Core elements according to the rules defined in the importer. This creates a “physical” copy of the metadata that isn’t linked to the source object in Fedora - changes in Omeka aren’t pushed back upstream into Fedora, and changes in Fedora don’t cascade down into Omeka.
-
If the datastream delivers content (e.g., an image), the plugin will check to see if it can find a “renderer” that knows how to display the content. Like the importers, the renderers are structured as an extensible API that ships with a couple of sensible defaults - out of the box, the plugin can display regular images (JPEGs, TIFs, PNGs, etc.) and JPEG2000 images. If a renderer exists for the content type in question, the plugin will display the content directly from Fedora. So, for example, if the datastream is a JPEG image, the plugin will add markup like this to the item show page:
Unlike the metadata datastreams, then, which are copied from Fedora, content datastreams pipe in data from Fedora on-the-fly, meaning that a change in Fedora will immediately propagate out to Omeka.
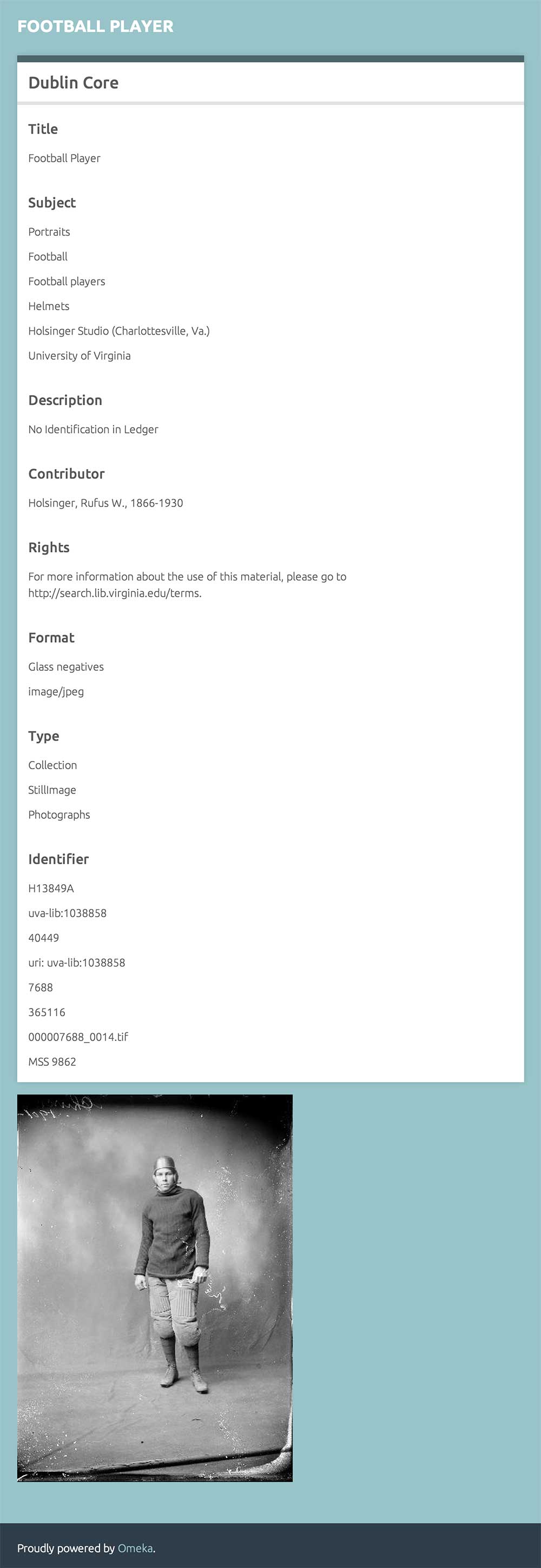
(See the image below for a sense of what the final result might look like - in this case, displaying an image from the Holsinger collection at UVa, with both a metadata and content datastream selected.)
For now, FedoraConnector is a pretty simple plugin. We’ve gone back and forth over the course of the last couple years about how to model the interaction between Omeka and Fedora. Should it just be a “pull” relationship (Fedora -> Omeka), or also a “push” relationship (Omeka -> Fedora)? Should the imported content in Omeka stay completely synchronized with Fedora, or should it be allowed to diverge for presentational purposes? These are tricky questions. Implementations of Fedora - and the workflows that intersect with it - can vary pretty widely from one institution to the next. The current set of features was built in response to specific needs here at UVa, but we’ve been talking recently with folks at a couple of other institutions who are interested in experimenting with variations on the same basic theme.
So, to that end, if you’re use Fedora and Omeka and interested in wiring them together - we’d love to hear from you! Specifically, how exactly do you use Fedora, and what type of relationship between the two services would be most useful? With a more complete picture of what would be useful, I suspect that a handful of pretty surgical interventions would be enough to accommodate most use patterns. In the meantime, be sure to file a ticket on the issue tracker if you find bugs or think of other features that would be useful.