
SolrSearch 2.0
Today we’re pleased to announce version 2.0 of the SolrSearch plugin for Omeka! SolrSearch replaces the default search interface in Omeka with one powered by Solr, a blazing-fast search engine that supports advanced features like hit highlighting and faceting. In most cases, Omeka’s built-in searching capabilities work great, but there are a couple of situations where it might make sense to take a look at Solr:
-
When you have a really large collection - many tens or hundreds of thousands of items - and want something scales a bit better than the default solution.
-
When your metadata contains a lot of text content and you want to take advantage of Solr’s hit highlighting functionality, which makes it possible to display a preview snippet from each of the matching records.
-
When your site makes heavy use of content taxonomies - collections, tags, item types, etc. - and you want to use Solr’s faceting capabilities, which make it possible for users to progressively narrow down search results by adding on filters that crop out records that don’t fall into certain categories. Stuff like - show me all items in “Collection 1”, tagged with “tag 2”, and so forth.
To use SolrSearch, you’ll need access to an installation of Solr 4. To make deployment easy, the plugin includes a preconfigured “core” template, which contains all the configuration files necessary to index content from Omeka. Once the plugin is installed, just copy-and-paste the core into your Solr home directory, fill out the configuration forms, and click the button to index your content in Solr.
Once everything’s up and running, SolrSearch will automatically intercept search queries that are entered into the regular Omeka “Search” box and redirect them to a custom interface, which exposes all the bells and whistles provided by Solr. Here’s what the end result looks like in the “Seasons” theme, querying against a test collection that contains the last few posts from this blog, which include lots of exciting Ivanhoe-related news:

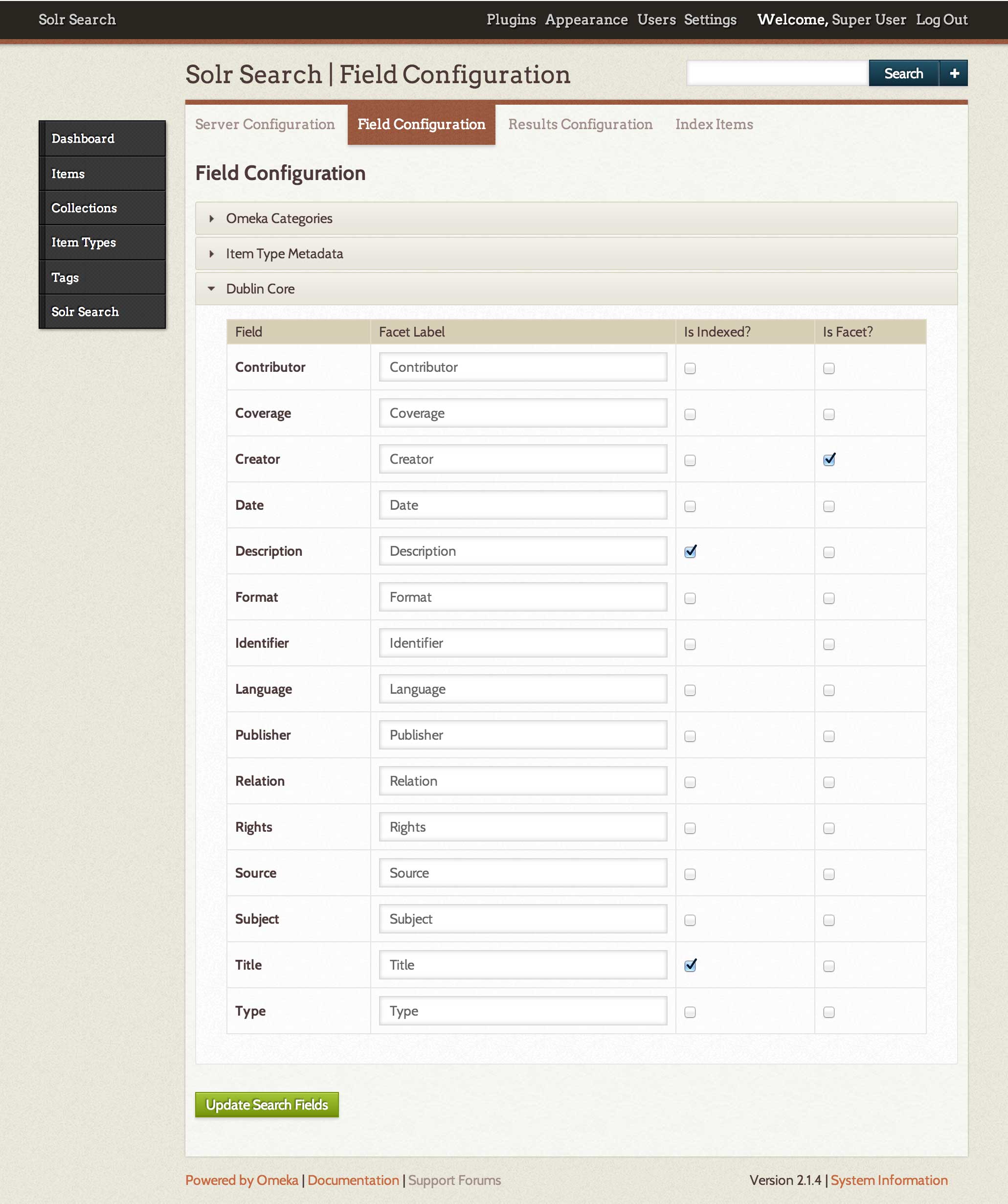
Out of the box, SolrSearch knows how to index three types of content: (1) Omeka items, (2) pages created with the Simple Pages plugin, and (3) exhibits (and exhibit page content) created with the Exhibit Builder plugin. Since regular Omeka items are the most common (and structurally complex) type of content, the plugin includes a point-and-click interface that makes it easy to configure exactly how the items are stored in Solr - which elements are indexed, and which elements should be used as facets:
Meanwhile, if you have content housed in database tables controlled by other plugins that you want to vacuum up into the index, SolrSearch ships with an “addons” system (devised by my brilliant partner in crime Eric Rochester), which makes it possible to tell SolrSearch how to index other types of content just by adding little JSON documents that describe the schema. For example, registering Simple Pages is as simple is this:
And the system even scales up to handle more complicated data models, like the parent-child relationship between “pages” and “page blocks” in ExhibitBuilder, or between “exhibits” and “records” in Neatline.
Anyhow, grab the built package from the Omeka addons repository or clone the repository from GitHub. As always, if you find bugs or think of useful features, be sure to file a ticket on the issue tracker!